
基础总结-STL相关
[TOC]
迭代器
- 迭代器是一种smart point;
- 迭代器主基本的编程工作就是对operator*,operator->,++, –,==,!=等操作符选择性的进行重载;
迭代器相应型别
迭代器相应型别是指: 迭代器所指之物的型别; 迭代器所指类型的型别称之为value type, 如果算法中要声明一个变量,以”迭代器所指对象的型别”为型别,如何做?
- 解决办法1: 使用function template的参数推导机制;
template <class I, class T>
void func_impl(I iter, T t)
{
T temp; //这里的T 就是迭代器所指之物的型别 本例为int
}
template <class T>
inline void func(I iter)
{
func_impl(iter, *iter);
}
//test
int i;
func(&i);
说明:
- 使用模板参数推导机制,只可以推到参数,却很难推导函数的返回值型别;
- 解决方法2: 声明为内嵌类型型别
template <class T>
struct MyIter
{
typedef T value_type; //内嵌型别声明(nested type)
T* ptr;
MyIter(T*p = nullptr) : ptr(p)
{
}
}
template <class T>
typename T::value_type func(T iter)
{
return *iter;
}
//test
MyIter<int> ite(new int(8));
cout << func(ite);
说明:
-
func的返回类型必须加上typename,因为T是一个模板参数,在他被编译器具现化之前,编译器并不知道MyIter
::value_type具体代表着一个什么(member function or data member); -
关键词typename告诉编译器这是一个型别,才可以通过编译;
-
缺点:并不是所有迭代器都是class type,原生的指针就不是,如果不是class; type那就没有办法定义为内嵌类型;而STL是必须要接受raw pointer作为一种迭代器的;
那么,有没有办法把上面的一般化概念针对特定情况(例如针对原生指针)做特殊化处理呢?
答案: 模板的派特华可以做到!
- “萃取”
template <class T>
struct iterator_traits
{
typedef typename ::value_type value_type;
}
//偏特化版本 可以处理迭代器是原生指针
template <class T>
struct iterator_traits<T*>
{
typedef T value_type;
}
//偏特化版本, 可以处理"针对常数对象的指针"
//当迭代器是一个pointer-to-const时, 萃取出来的是T 而非const T;
template <class T>
struct iterator_traits<const T*>
{
typedef T value_type;
}
//如果I定义了自己的value type,那么先前的那个func可以改写为:
template <class T>
typename interator_traits<I>::value_type func(I ite)
{
return *ite;
}
说明:
- 这里”萃取”的意义就是,如果I定义的有自己的value_type, 那么通过这个traits的作用, 萃取出来的value_type 就是I::value_type;
常用迭代器内部型别
常用迭代器相应型别有5种: value_type, difference_type, pointer, reference, iterator category ;
你希望你所开发的容器和STL水乳交融, 一定要为你的容器迭代器定义这五种相应的型别, traits会很容易的萃取出来:
template <class T>
struct iterator_traits
{
typedef typename T::iterator_category iterator_category; //
typedef typename T::value_type value_type; //迭代器所指对象的型别
typedef typename T::difference_type difference_type; //表示两个迭代器之间的距离,也可以用来表示迭代器的最大容量;
typedef typename T::pointer pointer;
typedef typename T::reference reference; //如果P是一个constant iterators 那么*p就是const T& 即所谓reference type
}
迭代器分类
根据移动特性和施行操作, 迭代器被分为五类:
- Input iterator: 这种迭代器所指的对象,不允许外接改变,只读(read only);
- Output iterator:唯写 write only
- Forward iterator: 允许”写入型”算法, 例如 replace在此种迭代器所形成的区间上进行读写操作;
- Bidirectional iterator: 可双向移动, 某些算法需要逆向走访某个迭代器区间, 可以使用此迭代器;
- Random Access Iterator: 前面四种仅供应一部分指针算术能力(前三个支持operator++, 第四种再加上operator–), 这一种则涵盖了所有指针算术能力, 包括: p+n, p-n, p[n], p1-p2, p1 < p2;
STL概述
容器分类
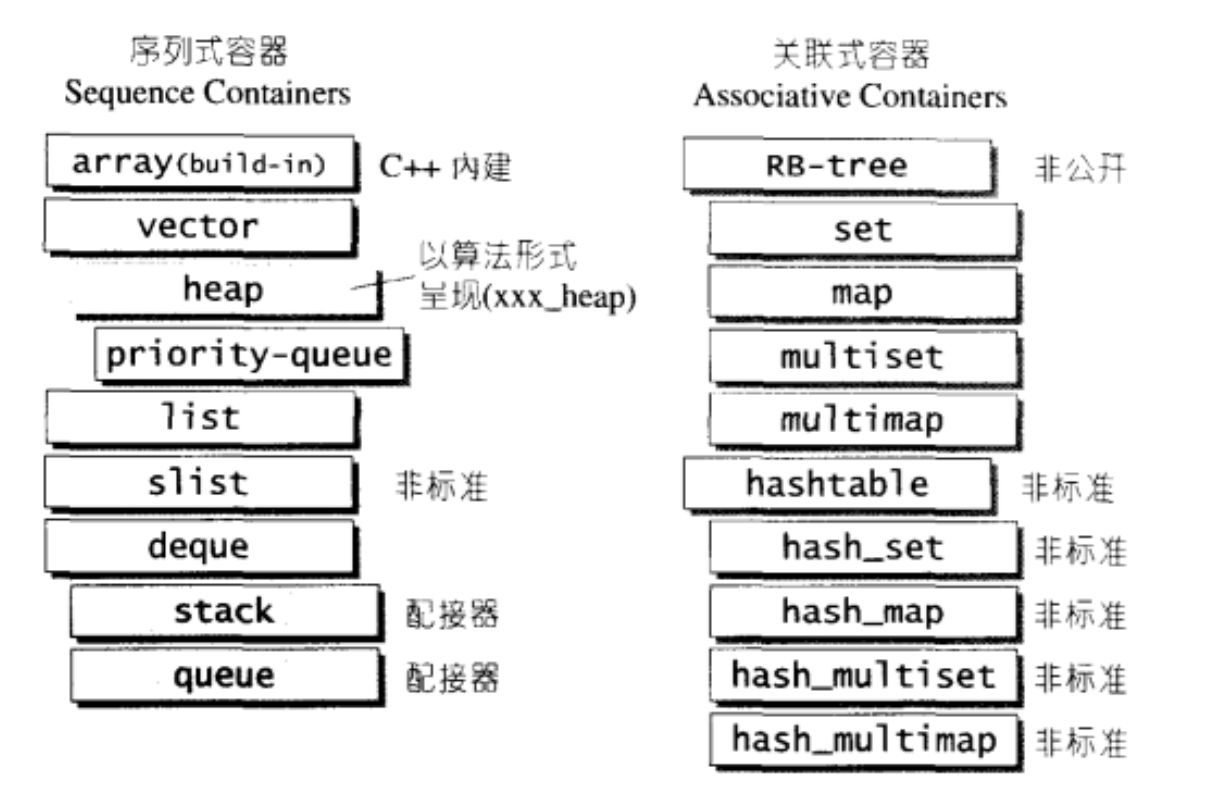
vector
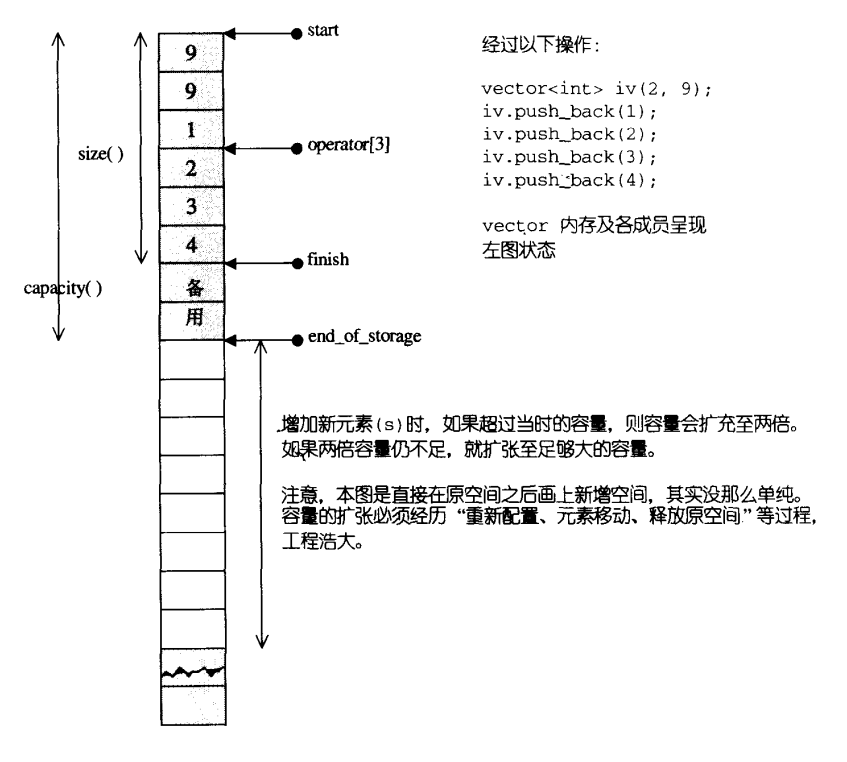
- std::vector 是一种序列容器,是对大小可变数组的封装。
- 数组中的元素是连续存储的,所以除了能够通过迭代器访问外,还可以通过常规的指针偏移量访问元素。换句话说,可以将指向 vector 元素的指针传入以指向数组元素的指针作为参数的函数。
- vector会在需要时候调整内存大小;
时间复杂度
- vector随机访问时间复杂度O(1);
- 在尾部增加删除元素平摊O(1);
- 增删元素 - 至 vector 尾部的线性距离 O(n);
注意点
-
vector中resize和reserve的区别?
resize: 调整容器大小,使其能够容纳count个元素;resize的时候可以携带初始值。resize和容器的size息息相关,调用resize(n)后,容器的size即为n; 至于是否影响capacity,取决于调整之后的容器的size是否大于capacity。
reserve: reserve和容器的vector息息相关,调用reserve(n)后,若容器的capacity<n,则重新分配内存空间,从而使得capacity等于n,reserve调整的capacity的大小。
- 所谓动态增加空间大小,并不是在原来空间之后接续新空间;而是以原来大小的两倍另外配置一块较大的空间;然后把原来的内容拷贝过来;然后释放原有空间;
- 对于vector一旦重新配置内存空间,指向原来vector的原来迭代器都会失效;
接口说明
- shrink_to_fit() 请删除未使用的容量. 这是一个不具约束力的要求,减少capacity size;
- data() 返回指向容器内部用于存储自身元素的数组的直接指针。如果容器对象是 const 限定的,函数返回指向 const value_type 类型的指针,否则返回指向 value_type 类型的指针;
- reserve 在插入元素的时候,如果提前知道元素的个数,先用reserve提前分配元素空间,可以有效提高效率;因为在insert的时候,每次都可能分配空间发生数据拷贝移动!
List
结构示意图:
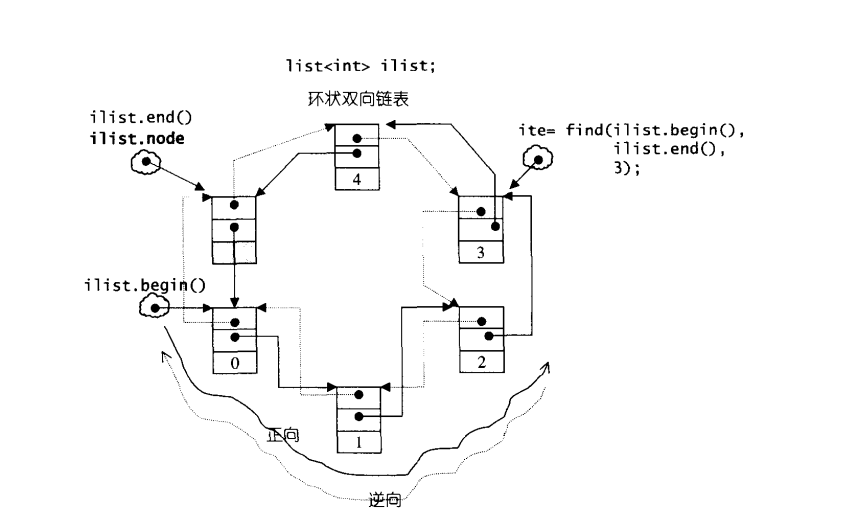
列表(List)是一个允许在序列中任何一处位置以常量耗时插入或删除元素且可以双向迭代的顺序容器(Sequence container)。
std::list 是一个双向链表(double linked-list), 而且是一个环状双向链表,只需要一个指针,便可以完整表现整个链表;存储空间无需连续;迭代器必须具备前移、后移的能力,所以list提供的是Bidrectional Iterator;
std::list 是双向环形链表,怎么满足STL要求的“前闭后开”的区间要求呢?怎么实现Begin和End这些函数呢?
很简单,list刻意在尾端添加了一个空白节点(node)看上面的示意图;
操作说明:
- 每次插入或者删除一个元素,就仅仅配置和释放一个元素空间;不存在元素移动等情况;
- list插入操作和接合操作(splice)都不会造成原有的list迭代器失效;
- 相比于其它顺序容器的主要缺点是它们不能够通过元素在容器中的位置直接访问(Direct access)元素。举个例子:如果想访问一个列表中的第六个元素,那么就必须从一个已知位置(比如开头或末尾)处开始迭代,这会消耗与两个位置之间距间相关的线性时间。而且它们还为保存各个元素间的链接信息消耗更多额外的内存(这点对由小尺寸元素组成的大列表尤为明显)。
- 从 C++11 开始,你也可以使用 emplace_front 及 emplace_back 分别向列表头或尾插入一个新的元素;
这里说一下emplace系列函数,vector,list,set,map等等容器都提供了emplace系列接口,这些接口和原来的Insert等接口的区别就是emplace就地构造元素,仅仅调用构造函数,即可完成插入!而push系列的函数,则需要构造、拷贝等;
emplace系列函数,效率明显更高,在C++11中尽量使用emplace系列函数;详细性能分析点这里
- list 类模板包含了由标准容器定义的 size 及 empty 函数。这里有一点必须要注意:size 函数的时间复杂度为 O(n)(从 C++11 开始,时间复杂度变为 O(1))。所以,如果你想简单判断一个列表是否为空,可以使用 empty 而不是 检查它的大小是否为 0。如果希望保证当前列表是空的,可以使用 clear 函数。
- sort 成员函数对列表进行排序,该操作时间复杂度保证为 O(nlogn);使用的是快速排序;
重要:注意,标准库中提供的 std::sort 排序函数需要容器支持随机访问迭代器,而 list 模板类并未提供该支持(直接原因是 list 提供的迭代器不支持 operator- 操作符函数),所以 std::sort 不支持对 list 的排序。
- unique函数只能删除容器中的所有连续重复元素,仅仅留下每组等值元素中的第一个元素;不连续重复的不会删除;
- merge合并两个list,前提是两个容器必须是有序排列过;时间复杂度:o(n);
forward_list
正向列表(Forward list)是一个允许在序列中任何一处位置以常量耗时插入或删除元素的顺序容器(Sequence container)。
容性特性:
- 顺序序列: 顺序容器中的元素按照严格的线性顺序排序。可以通过元素在序列中的位置访问对应的元素。
- 单链表: 容器中的每个元素保存了定位后一个元素及一个元素的信息,允许在任何一处位置以常量耗时进行插入或删除操作,但不能进行直接随机访问(Direct random access);
- 增加或移动正向列表中的元素不会使指向它们的指针、引用、迭代器失效,只有当对应的元素被销毁时才会如此。
与list的异同
Forward list 容器采用的是单链表(Singly-linked lists)数据库构。单链表可以保存以不同且无关的储存位置容纳的元素。元素间的顺序是通过各个元素中指向下一个元素的链接这一联系维护的。 主要的区别就是 std:: list 的元素中不仅保存了指向下一个元素的链接,还保存了指向上一个元素的链接,这使得 std::list 允许双向迭代,但消耗更多的存储空间且在插入删除元素时会有稍高(Slight higher)的耗时。因此 std::forward_list 对象比 std::list 对象更高效,尽管它们只能正向迭代。
注意
- forward_list 类模板是专为极度考虑性能的程序而设计的,它就跟自实现的C型单链表(C-style singly-linked list)一样高效。甚至为了性能,它是唯一一个缺少 size 成员函数的标准容器:这是出于其单链表的性质,如果拥有 size 成员函数,就必须消耗常量时间来维护一个用于保存当前容器大小的内部计数器,这会消耗更多的存储空间,且使得插入及删除操作略微降低性能。如果想获得 forward_list 的大小,可以使用 std::distance 算法且传递 forward_list::begin 及 forward_list::end 参数,该操作的时间复杂度为 O(n)。
- 对任意列表(std::list)进行插入或删除元素操作需要访问插入位置前的元素,但对 forward_list 来说访问该元素没有常数时间(Constant-time)的方法。因为这个原因,对传递给清除(Erase)、拼接(Splice)等成员函数的范围参数作了修改,这些范围必须为开区间(即不包括末尾元素的同时也不包括起始元素)。
- sort排序 在该操作的整个过程中,不会涉及任何元素的构造、析构或拷贝,仅仅是在容器内部移动元素。时间复杂度近似为 O(nlogn),其中 n 为容器的大小。
deque
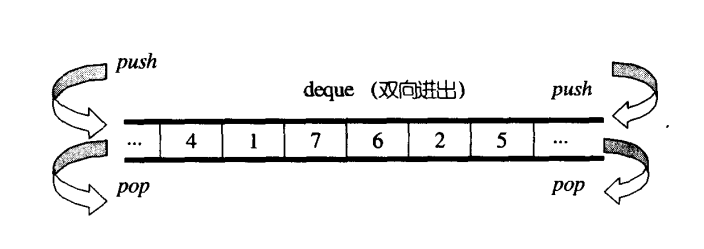
- deque 是双端队列;是一个大小可以动态变化(Dynamic size)且可以在两端扩展或收缩的顺序容器。
- vector是单项开口的连续线性空间;deque则是一种双向开口的连续线性空间;所谓双向开口:意思是可以在头尾两端分别做元素的插入和删除操作;
- deque允许以常数时间对其头端进行元素的插入和移除操作;
- deque也没用容量(capacity)的概念;因为它是以动态地分段连续空间组合而成;随时可以增加一段新的空间并连接起来;
- deque的迭代器是Ramdon Access Iterator,但是其迭代器不是一般的指针,这会影响到各个运算层面;很复杂;除非必要,尽量使用vector而非deque;
容器特性
- 顺序性:顺序容器中的元素按照严格的线性顺序排序。可以通过元素在序列中的位置访问对应的元素。
- 动态数组:通常采用动态数组这一数据结构。支持对序列中的任意元素进行快速直接访问。操供了在序列末尾相对快速地添加/删除元素的操作。
- 双端队列都允许通过随机迭代器直接访问各个元素,且内部的存储空间会按需求自动地扩展或收缩。
- 容器实际分配的内存数超过容纳当前所有有效元素所需的,因为额外的内存将被未来增长的部分所使用。就因为这点,当插入元素时,容器不需要太频繁地分配内存。
- 相比向量,双端队列不保证内部的元素是按连续的存储空间存储的,因此,不允许对指针直接做偏移操作来直接访问元素;
- 双端队列中的元素被零散地保存在不同的存储块中,容器内部会保存一些必要的数据使得可以以恒定时间及一个统一的顺序接口直接访问任意元素;
内存结构
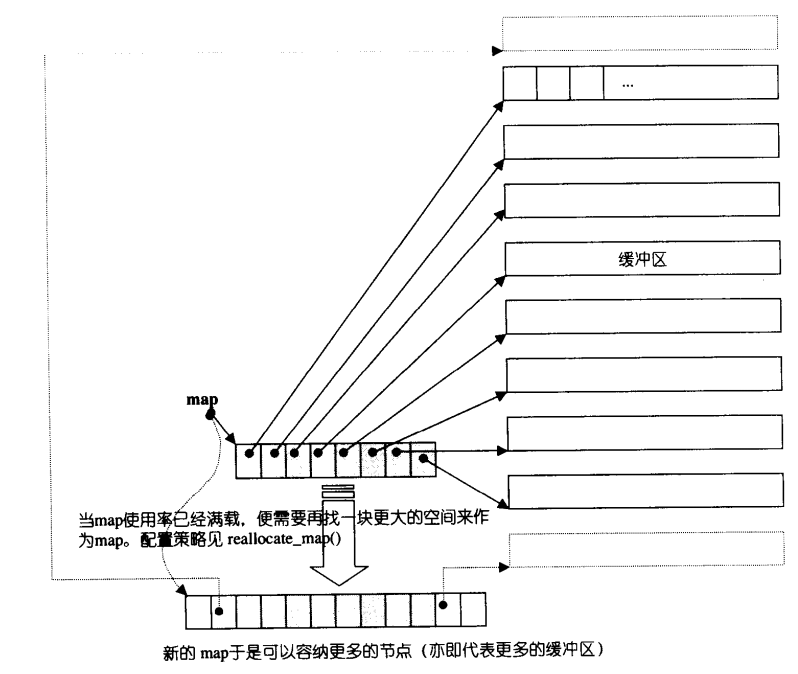
内存结构说明
- deque采用一块所谓的map作为主控, 这里所谓map不是STL中的map, 而是一块连续空间;
- map内部的每一个元素都是一个指针, 指向另外一段较大的连续线性空间, 称为缓冲区;
- 缓冲区才是deque的存储空间主体;
- STL运行指定缓存区的大小, 默认0表示使用512bytes缓冲区.
接口分析
- 对于大量涉及在除了起始或末尾以外的其它任意位置插入或删除元素的操作,相比列表(std::list)及正向列表(std::forward_list),deque 所表现出的性能是极差的,且操作前后的迭代器、引用的一致性较低。
- max_size 接口可以返回deque能够容纳的最大元素个数;是一个当前容器能够达到的受限于操作系统或编译器的最大可能大小。但实事上容器并不保证能够达到这个大小:在达到这个上限之前,已经出现内存分配失败。
stack
栈(Stack)是一个容器适配器(Container adaptor)类型,被特别设计用来运行于LIFO(Last-in first-out)场景,在该场景中,只能从容器末尾添加(Insert)或提取(Extract)元素。
结构示意图:
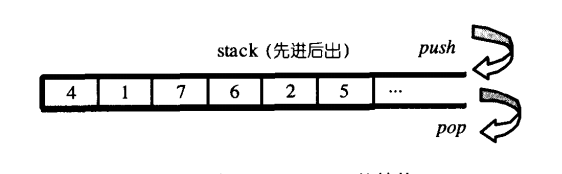
stack 通常被实现为容器适配器,即使用一个特定容器类的封装对象作为它的底层容器。stack 提供了一系列成员函数用于操作它的元素,只能从容器“后面”压进(Push)元素或从容器“后面”提取(Pop)元素。容器中的“后面”位置也被称为“栈顶”。 用来实现栈的底层容器必须满足顺序容器的所有必要条件。同时,它还必须提供以下语义的成员函数:
back()
push_back()
pop_back()
满足上述条件的标准容器有 std::vector、std::deque 及 std::list,如果未特别指定 stack 的底层容器,标准容器 std::deque 将被使用。
- 只有最顶端外,stack允许新增元素,移除元素,取得最顶端元素;除了顶端没有任何地方可以存取stack的其他元素;换言之就是stack不允许遍历;
- deque双向开口,以deque为底部结构并封闭其中一端的开口;便轻而易举地形成了一个stack;stack的底部实现就是deque;
- stack没有迭代器;
queue
队列(Queue)是一个容器适配器(Container adaptor)类型,被特别设计用来运行于FIFO(First-in first-out)场景,在该场景中,只能从容器一端添加(Insert)元素,而在另一端提取(Extract)元素。
结构示意图:
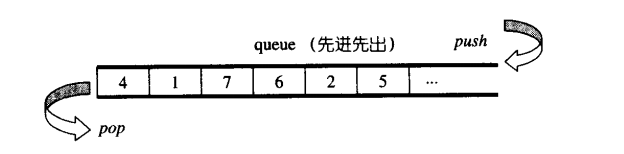
queue 通常被实现为容器适配器,即使用一个特定容器类的封装对象作为它的底层容器。queue 提供了一系列成员函数用于操作它的元素,只能从容器“后面”压进(Push)元素,从容器“前面”提取(Pop)元素。 用来实现队列的底层容器必须满足顺序容器的所有必要条件。同时,它还必须提供以下语义的成员函数:
front()
back()
push_back()
pop_front()
满足上述条件的标准容器有 std::deque 及 std::list,如果未特别指定 queue 的底层容器,标准容器 std::deque 将被使用。
- 允许新增元素,移除元素从最低端加入元素,取出最顶端元素;
- queue不允许遍历;不提供迭代器;
- 如果以deque作为其底层结构,封闭其底端的出口,顶端的入口即可;
std::array
数组(Array)是一个固定大小(Fixed-size)的顺序容器(Sequence container)。容器容纳了具体(Specific)数目的元素,这些元素逐个排列在一个严格的线性序列中;
容性特性
顺序序列(Sequence)
顺序容器中的元素按照严格的线性顺序排序。可以通过元素在序列中的位置访问对应的元素。
连续存储空间(Contiguous storage)
所有元素存储在一个连续的内存位置处,使得可以以常量时间随机访问元素。指向元素的指针可以通过偏移访问其它元素。
固定大小的聚集体(Fixed-size aggregate)
容器使用隐式(Implicit)构造函数(Constructor)及析构函数(Destructor)来静态地分配所需的存储空间。它的大小是一个编译时(Compile-time)确定的常量。除了自身所需外,不会消耗额外的内存或时间。
详细说明
- 在 array 容器内部,不会保存除了元素的任意其它数据(甚至没保存容器的大小,这个是一个模板参数,在编译时就已固定)。该容器同由言语中的括号语义([])定义的普通数组一样高效;
- array 仅仅是为普通数组添加了一些成员或全局函数,这使得数组能够被当成标准容器来使用;
- 区别于其它标准容器,array 拥有一个固定的大小,且不需要通过内存分配器(Allocator)管理元素的储存空间。它是一个封装了固定数量元素的数组的聚合类型(Aggregate)。因此,array 不能被动态地扩展或压缩。
- 区别于其它标准容器,交换(Swap)两个 array 容器是一个线性操作(即时间复杂度为 O(n)),涉及分别交换范围内的所有元素,这通常被认为是一个低效的操作。
- array 容器唯一具有的另一个特征是:可以把 array 容器当成一个多元组(Tuple)对象。在头文件
中,通过重载全局函数 get 使得通过 get 访问 array 中的元素时,array 容器就像一个多元组。
priority_queue
介绍priority_queue就不得不说heap, 这个是priority_queue真正的幕后推手!
heap
- 所谓的binary heap就是一种complete binary tree(完全二叉树), 关于堆分为大根堆(max_heap)和小根堆(min_heap); 关于堆的生成堆, 调整堆, push_heap, pop_heap, sort_heap等等算法 这里不再赘述了, 数据结构部分已经总结过;
- heap 没有迭代器, heap所有元素都必须遵循特别的排列规则, 所以heap不提供遍历功能, 也不提供迭代器;
概述
- priority_queue 是一个拥有权值观念的queue, 它允许加入新元素, 移除旧元素, 审视元素值等功能;
- 也是一个queue, 所以允许在底端加入元素, 并从顶端取出元素, 除此之外别无其他存取元素的途径;
- priority_queue内部元素, 不是按照push进去的顺序排列的, 而是自动依照元素的权值排列(通常权值就是实际上的值); 权值最高者, 排在最前面;
- 缺省情况下, priority_queue利用一个max_heap完成;后者是一个以vector表现的complete binary tree;
结构
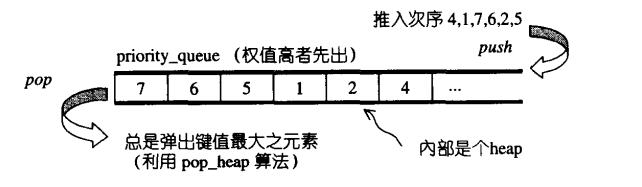
- priority_queue完全以底部容器为依据, 再加上heap处理规则;
tree
二叉树分类
二叉搜索树(binary search tree)
二叉查找树(BinarySearch Tree,也叫二叉搜索树,或称二叉排序树Binary Sort Tree)或者是一棵空树,或者是具有下列性质的二叉树:
- 若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 任意节点的左、右子树也分别为二叉查找树。
- 二叉查找树性质:对二叉查找树进行中序遍历,即可得到有序的数列。
平衡二叉排序树
也许因为输入值不够随机, 或者经过一些插入删除操作, 二叉搜索树可能失去平衡, 造成搜索效率很低的情况;
AVl-tree, RB-tree, AA-tree均可实现平衡二叉搜索树;
AVL tree
- 是一个加了额外平衡条件的二叉搜索树;
- 其平衡条件确保了整颗树的深度为O(logN);
- 要求任何节点的左右子树高度相差最多1;
RB tree
RB tree 不仅仅是二叉搜索树, 还需要满足一下规则:
- 每个节点不是红就是黑;
- 根节点为黑色;
- 如果节点为红, 其子节点必须为黑;
- 任何一个节点至NULL(树尾端)的任何路径, 所含之黑节点数必须相同;
set
- 所有的元素都会根据元素的键值自动排序; set的键值就是实值;
- set不允许有两个相同的键值;
- set的迭代器不能够改变set的元素值; 因为改变元素的值, 关系到set的排序规则;
- set iterators 是一种constant iterator;
- set和list一样, 当客户端对它进行插入或者删除操作, 操作之前的迭代器在操作之后依然有效(除了被删除的那个);
- set的所有接口均使用RB tree的接口;
接口说明
- std::set::count set 类模板中的公共成员函数。返回容器中值等于 val 的元素的个数。因为 set 容器中所有元素都是唯一的,当前函数只能返回 1 或 0。
- lower_bound 返回指向容器中第一个值等于给定搜索值或在给定搜索值之后的元素的迭代器,即第一个等于或大于给定搜索值元素的迭代器。
map
- 所有的元素都会根据元素的键值自动排序;
- map的所有元素都是pair, 同时拥有实值(value) 和 键值(key);
- 和set一样, 通过迭代器修改map的键值也是不行的, 但是可以修改其实值;
- map的iterator既不是constant iterator也不是mutable iterator;
- map和list一样, 当客户端对它进行插入或者删除操作, 操作之前的迭代器在操作之后依然有效(除了被删除的那个);
multiset && multimap
- multiset的特性和用法和set完全相同, 唯一的区别是它允许键值重复, 因为插入的底层机制RB-Tree的insert_equal而非insert_unique;
- multimap的特性和用法和map完全相同, 唯一的区别是它允许键值重复, 因为插入的底层机制RB-Tree的insert_equal而非insert_unique;
总结
- 容器是以class templates完成, 算法以function templates完成, 仿函数是一种重载operator()的class template; 迭代器是一种将operator++和operator*等指针行为重载的class template;
- 容器身上和迭代器身上的配置器, 是一种class template;
参考:http://ibillxia.github.io/blog/2014/11/26/insight-into-stl-archive/
cuipf
